KVQA: Knowledge-aware Visual Question Answering
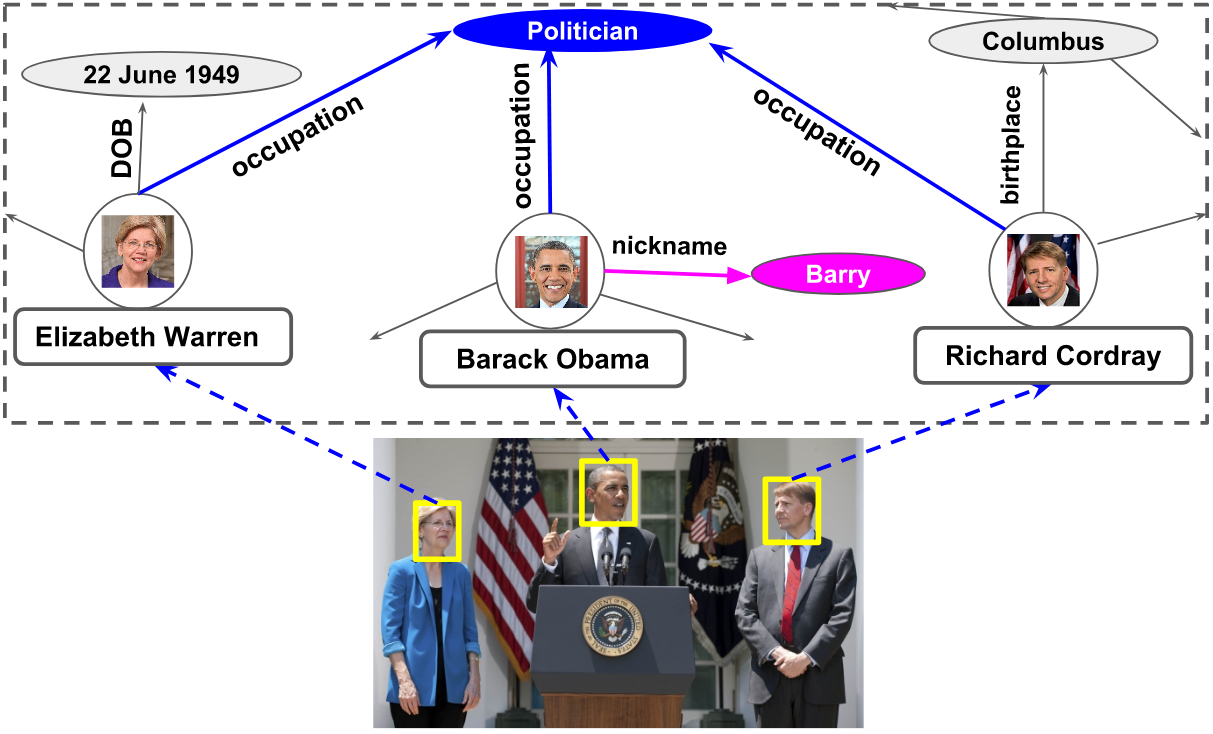
A: Richard Cordray
Q: Do all the people in the image have a common occupation?
A: Yes
Q: Who among the people in the image is called by the nickname Barry?
A: Person in the center
Motivation
Visual Question Answering (VQA) has emerged as an important problem spanning Computer Vision, Natural Language Processing and Artificial Intelligence (AI). In conventional VQA, one may ask questions about an image which can be answered purely based on its content. For example, given an image with people in it, a typical VQA question may inquire about the number of people in the image. More recently, there is growing interest in answering questions which require commonsense knowledge involv- ing common nouns (e.g., cats, dogs, microphones.) present in the image. In spite of this progress, the important problem of answering questions requiring world knowledge about named entities (e.g., Barack Obama, White House, United Nations.) in the image has not been addressed in prior research. We address this gap in this paper, and introduce KVQA – the first dataset for the task of World Knowledge-enabled VQA. KVQA consists of 183K question-answer pairs involving more than 18K named entities and 24K images. Questions in this dataset require multi-entity, multi-relation, and multi- hop reasoning over large Knowledge Graphs (KG) to arrive at an answer. To the best of our knowledge, KVQA is the largest dataset for exploring VQA over KG. Further, we also provide baseline performances using state-of-the-art methods on KVQA. We firmly believe that KVQA will spawn new avenues of research spanning the areas of vision, language, knowledge graphs, and more broadly AI.
Highlights
- The largest dataset for VQA over KG (as on November 14, 2018)
- An important but unexplored problem of VQA involving named entities in an image.
- Visual entity linking problem in web-scale
- Challenges for Computer Vision: face identification at web-scale
- Challenges for NLP: reasoning over KG
Dataset: explore more
 |

Dataset: downloads
KVQA1.0 - dataset images (25 GB)
KVQA1.0 - reference images (61 GB)
KVQA1.0 - dataset.json file (QA pairs and other info) (35 MB)
Preprocessed KG facts
README
Updates
Bibtex
If you use this dataset, please cite:
@InProceedings{shahMYP19,
author = "Sanket Shah, Anand Mishra, Naganand Yadati and Partha Pratim Talukdar",
title = "KVQA: Knowledge-Aware Visual Question Answering",
booktitle = "AAAI",
year = "2019",
}
Publications
Sanket Shah*, Anand Mishra*, Naganand Yadati, Partha Pratim Talukdar, KVQA: Knowledge-Aware Visual Question Answering, AAAI 2019 [pdf][Slides] (*: Equal contributions)
Acknowledgements
Authors would like to thank MHRD, Govt. of India and Intel Corporation for partly supporting this work.